ML Bench · 总报告
基于 Lean 4 + Mathlib 的机器学习理论 benchmark · 评测 LLM 的形式化判别与证明能力
本报告的三个核心点
- 题库已拓展到 70 题(统计学习理论:集中不等式、复杂度、优化、在线学习、信息论…)。
- 带「以上都不对」选项的多选题上,模型表现不尽人意;case study 发现主要问题在 hypothesis(假设)层面:必要假设被悄删时模型识别不出,反而合理化"它不必要"。
- 即便给了自然语言证明,模型仍很难写对 Lean proof(目前最佳 9/30)。
1. 题目纵览
正式题库 70 题,取自统计学习理论教材 ch2 至 ch17:
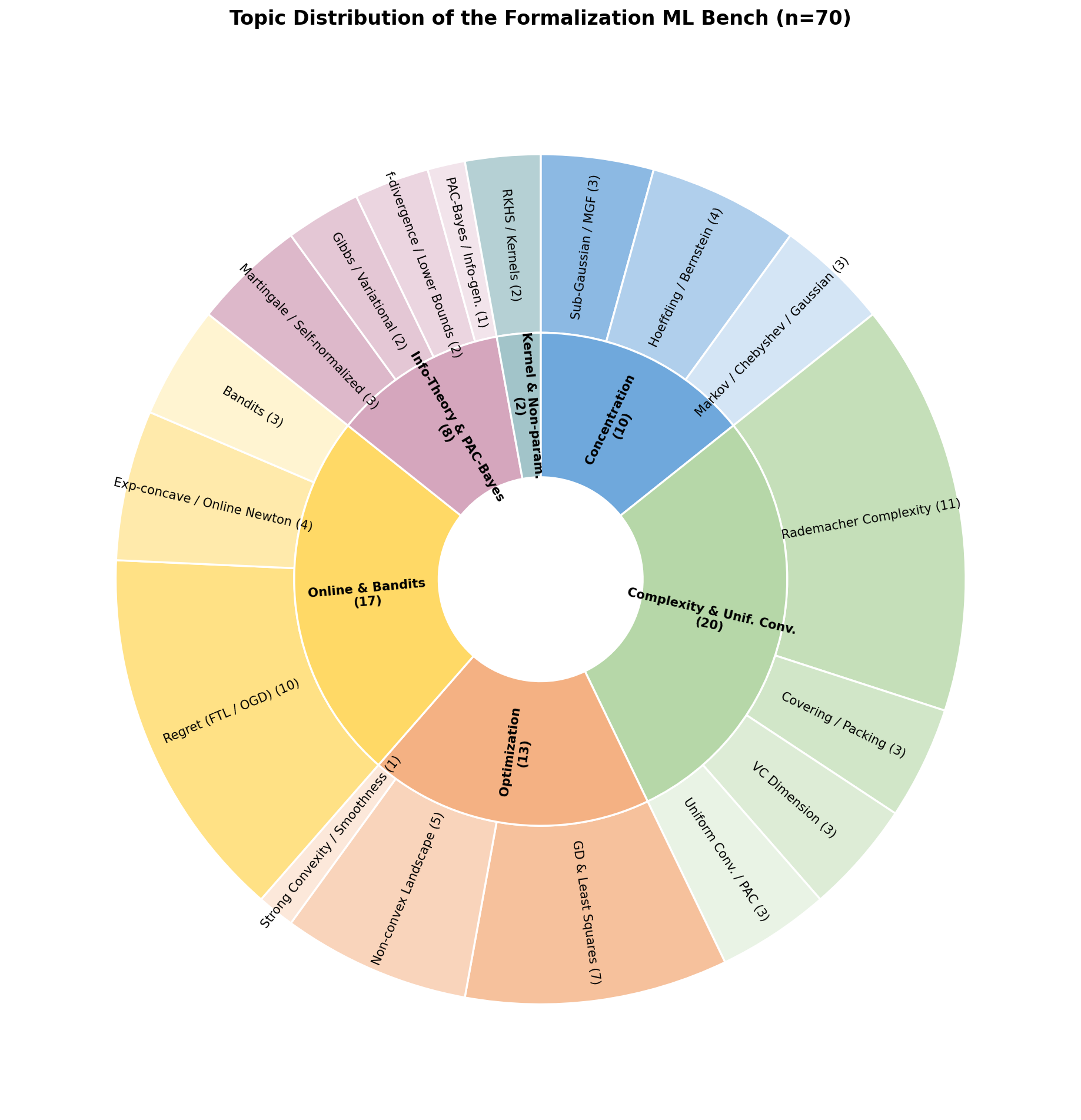
| 主题 | 题数 | 占比 | 主题 | 题数 | 占比 |
|---|---|---|---|---|---|
| Complexity & Unif. Conv. | 20 | 29% | Concentration | 10 | 14% |
| Online & Bandits | 17 | 24% | Info-Theory & PAC-Bayes | 8 | 11% |
| Optimization | 13 | 19% | Kernel & Non-param. | 2 | 3% |
2. 主实验 1:Statement Verification(多选题)已完成
四选一:哪个 Lean 选项忠实形式化,或「以上都不对」。主表为平衡设定(一半题目正解是「以上都不对」):
| 模型 | 总正确率 | acc·real (有真解) | acc·「都不对」 (无真解) |
|---|---|---|---|
| Claude sonnet-4.6 | 0.800 | 0.971 | 0.629 |
| GPT-5.5 | 0.771 | 0.943 | 0.600 |
| GPT-5.4-mini | 0.586 | 0.229 | 0.943 |
| GPT-5.4-nano | 0.486 | 0.514 | 0.457 |
- Claude ≈ GPT-5.5 最强;能识别忠实选项,但在判定所有选项均有缺陷时表现较弱。
- mini 的高分主要来自对「以上都不对」的偏好性选择(acc·real 仅 0.23)。
- 另有正确率明显更低的更难设定(占比更高),详见 NOTA Ablation。
3. 主实验 2:Proof Verify(定理证明)初步 · 30 题
给定形式化陈述,模型生成 Lean 证明,以编译通过判对(proved / 30):
| 模型 | One-shot (wo/lib) | #iter=5 (wo/lib) | One-shot (w/lib) | #iter=5 (w/lib) |
|---|---|---|---|---|
| gpt-5.4-mini | 1/30 | 2/30 | 2/30 | 4/30 |
| claude-code (sonnet 4.6) | 4/30 | 7/30 | 6/30 | 9/30 |
| codex (GPT-5.5) | 3/30 | 4/30 | N/A | N/A |
注:上周数据(本周 claude-code 与 codex 额度受限);仅 30 题且主题有偏;70 题完整版下周更新。
主实验 2 详情 →4. Insight(with ablation)
- 模型会判断错 statement:给了 NL 陈述仍把"有缺陷的形式化"当忠实,多选题大量漏报。
- 处理 assumption 的能力明显不足:最大盲点是"必要假设被悄删"(NL 看不出),模型常合理化"它不必要"。
- false negative / positive 倾向不同:大模型保守(高漏报、近零误报);mini 相反(过度选择「以上都不对」,误报偏高)。
- 给定 Mathlib 后 proof behavior 变化:提供库后通过率提升(claude 4→6、7→9),转向复用库中定义与引理。
错题 Case Study(5 个真实漏报 + Lean diff)→
5. ML Lib(MLMath)已完成
- 底层 Lean 库:911 个声明(641 定理引理 + 214 定义)、19.3K 行、9 模块。
- 0 sorry / 0 自定义 axiom,完全建立在 Mathlib 之上。
6. 下一步
- 拓展题库 → 100 题。
- 测模型 proof 能力(补齐 70 题完整 proof 评测)。
- 加大多选题难度:adversarial 地挑选模型易错的题。
各子报告左上角有「← 返回总览」。数学公式由 MathJax(CDN)渲染,查看需联网。